Česká Raiffeisenbank potřebovala získat maximální kontrolu nad kapacitním plánováním své VMware platformy. Na jedné straně byla potřeba hledat úspory nad jednotlivými clustery a virtuálními stroji, na straně druhé stál požadavek zajištění vysoké dostupnosti. Jak jsme si s tím poradili a co konkrétně přineslo kapacitní plánování zákazníkovi?

Čas na kapacitní plánování
Jak už zaznělo, konfigurace VMware farmy Raiffesenbank neposkytovala detailní přehledy, z nichž by klientovi plynuly možnosti úspor v rámci clusterů a virtuálních strojů.
Banka chtěla hledat úspory také v promyšleném licencování základního software. V neposlední řadě ji trápilo, že auditní nález postrádal kapacitní plánování a pravidelný reporting dostupných zdrojů ve vztahu k vysoké dostupnosti.
V Raiffeisenbank se proto rozhodli využít zkušeností ORBITu s optimalizací a konsolidací virtuálních platforem a s naší expertní znalostí VMware platformy. Mohli také počítat s našimi detailními znalostmi interních systémů banky, které jsme získali při dřívějších projektech.
Průběh projektu
V první fázi bylo potřeba několik měsíců sbírat zátěžové metriky a konfigurace z VMware platformy. Zároveň jsme ladili engine pro konfiguraci.
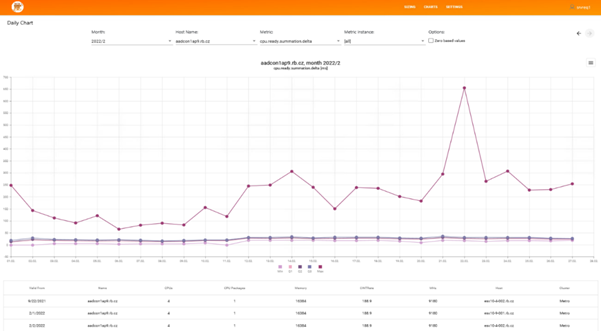
Grafické zobrazení jedné ze sbíraných metrik jako statistická analýza chování
Teprve po třech měsících jsme viděli skutečnou dlouhodobou situaci. Mohli jsme tak začít usuzovat na trendy v zátěži na úrovni hardware i virtuálních systémů a generovat první doporučení.
V celém procesu jsme se mohli opřít o nástroj ORBIT vResControl. Sami jsme si jej vyvinuli, aby nám pomáhal stanovit optimální konfigurace virtuálních strojů na základě statistického chování zátěže zdrojů.

Ukázka statistického vyhodnocení zátěže základních metrik
Na co si dát pozor
Při optimalizaci konfigurace virtuálního stroje zohledňujeme důležitou věc: je virtuální stroj zapojen do clusteru na úrovni operačního systému nebo aplikačního middleware s jiným strojem? A pokud ano, je to zapojení v režimu active/passive, nebo active/active? Kolik nodů je případně spojeno v celek takového clusteru?
V sázce je nepříjemná možnost, že pasivní stroje připravené pro převzetí zátěže vyhodnotíme jako osazené příliš mnoha zdroji, překonfigurujeme je na nižší hodnoty, a zničíme tak schopnost clusteru dosahovat vysoké dostupnosti. Informace o aplikačních clusterech proto musely být sesbírány a dodány do vResControl nástroje.
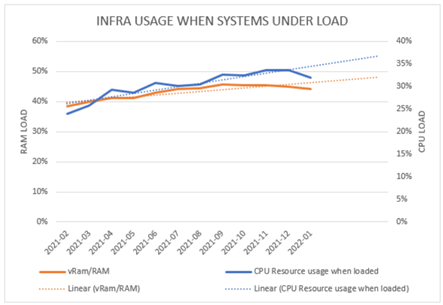
Celkový pohled na procentuální využití zdrojů virtuální farmy při vysoké celkové zátěži
Největším problémem při podobné službě však není technická část a sběr dat z platforem. Klíčová je logika vysoké dostupnosti na úrovni virtuální platformy nebo aplikačních clusterů. Bez její znalosti jsou technická data neužitečná. Při podobném projektu se proto vyplácí tlačit zákazníka hned od začátku k průběžnému dodávání kvalitních metadat (například z konfigurační databáze).
Kapacitní plánování v číslech
Raiffeisenbank nyní dokáže na základě 1500 doporučení měsíčně optimálně konfigurovat svých 3500 virtuálních strojů podle skutečné zátěže. A s rostoucí databází stovek milionů záznamů o zátěži nyní s dostatečným předstihem předvídá a plánuje dodatečné potřebné kapacity.
Pokud byste do databáze ukládali každou vteřinu jeden záznam o zátěži,
100 milionů záznamů byste nepřetržitě shromažďovali 3 roky, 2 měsíce a 1,5 dne.
Nám to trvá 24 hodin.
Nasazení průběžné služby kapacitního plánování VMware platformy tak proběhlo v požadovaném rozsahu a v předem dohodnutém termínu. Službu proto u zákazníka dále rozšiřujeme o reporting pro další platformy.


