Správa cloudu 1: Nepatchujte, redeployujte!

Cloud (ať už public nebo private) můžeme označit jako „softwarově definované datacentrum“, čímž se snažíme říct, že všechny elementy naší infrastruktury lze spravovat softwarově. Můžeme si ale vybrat, jak k tomu přistoupíme. Správa cloudu se dá dělat postaru – manuálně, nebo moderně – softwarově a s pomocí automatizace. O té bude následující minisérie článků.
Petros Georgiadis
Manuální správa cloudu aneb nepohodlná železná košile
Pracovat manuálně (bez automatizace) v on-premise datovém centru je běžná nepohodlná železná košile. Málokdo má totiž celé datové centrum „softwarově definované“, zatímco v cloudu to tak je od začátku.
V cloudu můžeme pracovat i hezky postaru – tzn. manuálně, pomalu, s rizikem zavlečení lidské chyby a se spoustou opakujících se aktivit – začneme na dev prostředí, pokračujeme přes test, integrační test, acceptance test, před-produkční test (pre-prod), až se konečně dopracujeme k produkčnímu prostředí (prod).
Často ovšem nemáme zajištěno, že pre-prod prostředí jsou identická s tím produkčním. Tím pádem nemáme ani jistotu, že provedený úkon, např. upgrade operačního systému (OS), nezavleče do systému nějakou změnu, která bude nekompatibilní s vaší aplikací. Taková situace by mohla mít za následek výpadek aplikace a následný rollback.
Dalším negativním aspektem manuální správy infrastruktury je značná pracnost a časová náročnost.

Uvedu vám příklad z PCI DSS certifikovaného prostředí. Norma vyžaduje, aby byly všechny operační systémy opatchovány alespoň jednou za tři měsíce. Pokud máte 60 serverů, updaty se musí provádět v noci ve dvou lidech (infra admin + aplikační specialista – na každou aplikaci musí být jiný aplikační specialista), což už je docela hodně probdělých nocí, stresů a vyhozených peněz.
Když se zeptám managera zodpovědného za provoz infrastruktury, jestli by chtěl tyto updaty automatizovat, odpověď zní, že pokud to bude dávat ekonomický smysl, tak určitě. Ale já vždy odpovídám, že smysl automatizace nespočívá jen v porovnání nákladů na vytvoření automatizovaného prostředí s náklady na člověka, který bude dalších pět let dohlížet na updaty.
Čas IT specialistů má být věnován rozvoji místo pracného udržování prostředí.
Navíc IT specialisté si dnes vybírají, jakou práci chtějí dělat. A je docela možné, že za 5 let už nebude nikdo, kdo by chtěl po nocích updatovat operační systémy. Není tedy na co čekat a pojďme se vrhnout na druhý způsob práce s cloudem.
Modernizace správy cloudu
Všechna cloudová prostředí (AWS, Azure, GCP, OpenStack, Proxmox, Kubernetes atd.) se dají ovládat programově pomocí jejich API. Nad nimi jsou postavena cloudová GUI a veškeré akce, které můžeme přes GUI udělat, můžeme provést přímo přes API.
Ne všichni IT specialisté jsou ale tak zdatnými programátory, aby volali cloudová API napřímo ze svého kódu. Proto existuje celá řada nástrojů, které nám tuto komunikaci zprostředkují, například AWS CLI, Azure CLI, Terraform, kubectl atd. To už se přitom velmi blížíme ke konceptu Infrastructure as a Code (IaC), o kterém jsme už v naší cloudové encyklopedii psali.
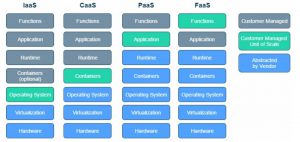
Pojďme se podívat, jak vypadá moderní správa cloudu – tedy jakým způsobem budeme v infrastruktuře vytvořené pomocí IaC patchovat operační systémy, používané platformy, potažmo nasazovat nové verze aplikací. Naše IT systémy můžeme do cloudu nasazovat prostřednictvím: 1) virtuálních serverů (virtual machine – VM), 2) kontejnerů nebo 3) serverless funkcí.

1) SPRÁVA CLOUDU & Virtuální servery
Jak už z názvu vyplývá, virtuální server je server. A když se řekne server, tak si běžný IT člověk představí něco hodně drahého, velkého a složitého, o co je třeba pečovat. Tahle premisa je skutečně pravdivá pro fyzický server, ale potenciálně škodlivá a omezující v případě serveru virtuálního.
Skutečná hodnota VM je v jeho funkcionalitě a v datech, která obsahuje. V ideálním případě by perzistentní data neměla být uložena přímo na daném VM, ale na nějakém externím uložišti nebo v databázi.
Funkcionalitu VM bychom měli spojovat spíše s aplikací, která tuto funkcionalitu vykonává, než se serverem samotným. Z toho nám vyplývá, že VM je jen něco, co nám umožní provozovat aplikaci a propojit ji s aplikačními daty a s vnějším světem.
Pets vs. cattle
Proč tedy existují virtuální servery, které běží spoustu let, mají své jméno, statickou IP adresu (kterou každý v týmu dobře zná) a IT administrátoři u nich vysedávají po nocích, aby je udržovali v dobré kondici?
Je to proto, že kompletně (manuálně) nainstalovat, nakonfigurovat a otestovat virtuální server není triviální záležitost. Když už je taková práce tedy jednou hotová, je snazší doinstalovávat upgrady a nové verze aplikace, než všechno zahodit a začít úplně od začátku. A tak se o naše virtuální servery staráme jako o domácí mazlíčky.
Zcela triviální není ani vytvoření a otestování instalačních skriptů. Ale platí, že když už jsme si tím jednou prošli, je následná opakovaná použitelnost daleko větší než v případě manuálně nainstalovaného VM.
Když už tedy máme instalace virtuálních serverů automatizované, můžeme nové VM „sázet jako Baťa cvičky“. Je nám přitom jedno, jestli vytvoříme jeden, tři nebo deset virtuálních serverů. A nemusíme se ani dvakrát rozmýšlet, co udělat se zastaralým VM – prostě ho zahodíme a nahradíme novým.
Golden image vs. bootstraping
Virtuální server se běžně startuje z nějakého image. Většinou se začíná z base image, který obsahuje konkrétní verzi operačního systému. Poté se instalují potřebné platformy (např. Java) a aplikace. Výsledný virtuální server si můžeme uložit jako nový image, který následně používáme pro start VM. Kompletně nainstalovanému image se říká golden image.
V cloudových prostředích máme také možnost automaticky doinstalovat potřebné platformy a aplikace hned po startu serveru pomocí cloud init scriptů. Takovému postupu se říká server bootstraping.
- Výhodou použití golden image je rychlý start nového VM. Nevýhodou je složitější proces upgradování jednotlivých komponent a vytváření nového image. Předpokladem pro efektivní používání golden image je existence CI/CD pipeliny, která automatizuje vytváření nových verzí.
- Pokud takovou CI/CD pipelinu nemáte k dispozici, použijte raději server bootstraping. Start serveru v takovém případě trvá déle (řádově jednotky minut) a musíte odolat pokušení updatovat hned po startu operační systém (např. příkazem sudo yum update). Také nezapomeňte definovat konkrétní verze všech komponent, které při startu doinstalováváte (viz obrázek).
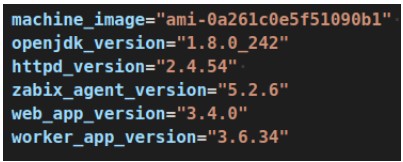
Správným postupem je udržovat pre-pro a produkční prostředí identické. Nainstalované verze jednotlivých komponent by se měly lišit pouze svou konfigurací – to znamená, že konfigurace by nikdy neměla být součástí image, ale měla by se stahovat zvenčí.
Můžete se inspirovat například návodem, jak vytvářet cloudové aplikace, na stránkách The Twelve Factor App.
Autoscaling
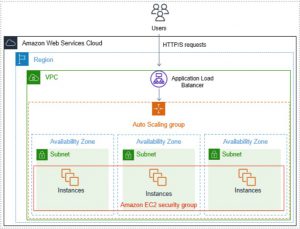
Když už umíme snadno vytvořit nový virtuální server, jak toho smysluplně využít? Cloudová prostředí nám poskytují platformy (Platform as a Service – PaaS), které udělají spoustu věcí za nás, což je hlavním důvodem, proč uvažujeme o využití public cloudu.
Virtuální server, který si nastartujete v public cloudu, nebude levnější než ten, který spustíte na vlastním fyzickém serveru. Na druhou stranu nám public cloud nabízí možnosti, kterých bychom dosahovali vlastními silami jen velmi těžko – třeba automatický start našeho virtuálního serveru v jednom z devíti dostupných datacenter v rámci jednoho regionu.
Abyste si otevřeli dveře k těmto možnostem, musí vaše aplikace splňovat dvě základní podmínky:
- Nesmíte uchovávat perzistentní data na lokálních discích virtuálního serveru.
- Nesmí vám záležet na tom, jestli daná konkrétní instance VM běží nebo neběží – tzn. VM jsou navzájem zastupitelné a můžete je přidávat a odebírat dle potřeby.
Po splnění obou podmínek můžete používat např. auto scaling groupy, které poskytují následující výhody:
- hlídají minimální požadovaný počet zdravých VM,
- odstraňují VM, které neprojdou přes health check,
- přidávají a ubírají VM podle jejich aktuální utilizace na základě různých metrik (např. využití CPU, RAM, počtu požadavků směřujících na VM),
- automaticky registrují/deregistrují VM instance do load balanceru,
- v případě výpadku datacentra nastartují chybějící VM ve zbývajících dostupných datacentrech,
- zajistí nasazení nových verzí bez výpadků systému (ve spojení s load balancerem).
2) SPRÁVA CLOUDU & Kontejnery
Kontejnery jsou o poznání mladší technologií než serverová virtualizace, a tím pádem daleko lépe přizpůsobená dnešní automatizované době.
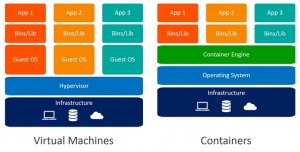
Na následujícím obrázku je vidět, že každý virtuální server obsahuje vlastní operační systém, knihovny a vlastní aplikace, kdežto kontejner obsahuje pouze knihovny a aplikaci. (Díky tomu má typický VM image velikost desítek GB, kdežto typický kontejner image jen stovky MB.)
Koncept kontejnerové technologie naštěstí uživatele upozorňuje, že životnost kontejneru se může pohybovat v řádech minut. Proto nemá smysl se připojovat dovnitř a dělat v něm nějaké manuální zásahy.
Skoro bych řekl, že myšlenka postradatelnosti instance VM přišla ze světa kontejnerů a je to příklad toho, jak novější technologie pomohla modernizovat tu předchozí (něco jako když snowboardy inspirovaly vznik carvingových lyží a dnes používáme obojí).
Kontejner image
Tak jako existují VM image, existují i kontejner image. Ale s jedním zásadním rozdílem: kontejner image by měl být vždy golden image, tzn. že by v sobě měl obsahovat všechny potřebné knihovny a verze aplikace. (Čistě teoreticky bychom mohli něco doinstalovávat i po startu kontejneru, ale tato myšlenka se mi zdá „vulgární“, a tak ji ani nebudu dále rozvíjet.)
Kontejnery by měly startovat velmi rychle (v rámci sekund), čehož dosáhnete jen s hotovým imagem. Ten následně nahrajte do repositáře (např. Nexus a jFrog v on-premise prostředí, nebo Docker Hub, AWS ECR, Azure CR v rámci cloudových služeb), odkud můžete vaši aplikaci a její různé verze snadno distribuovat.
Platformy na správu kontejnerů
Kontejnery musíme spouštět na nějakém kontejner enginu. Docker Engine nebo Docker Compose jsou vhodné jen na lokální development a testování, ale ne na provoz aplikace.
K produkčnímu nasazení kontejnéru slouží:
- open source Kubernetes (k8s), který můžete provozovat v on-premise, v cloudu nebo si ho kupovat jako službu (PaaS) od celé řady různých poskytovatelů,
- proprietární řešení od public cloud poskytovatelů (např. AWS ECS, Azure Service Fabric, Google Cloud Run a další), které bývají velmi dobře integrované s dalšími službami daného cloudu.
Pokud se rozhodnete provozovat nějakou kontejnerovou platformu sami, tak to s největší pravděpodobností budete dělat na virtuálních serverech. Proto mějte na paměti, že byste měli zautomatizovat samotné nasazení této platformy, jak jsme to popsali v odstavci Virtuální servery.
3) SPRÁVA CLOUDU & Serverless funkce
Serverless funkce je v podstatě kód v určitém programovacím jazyku + potřebné knihovny daného jazyka. Tyto funkce jsou spojeny hlavně s public cloud providery (např. AWS Lambda, Azure Functions, GCP Functions), ale najdeme i kubernetes projekty, které nám umožní provozovat serverless funkce v našem k8s clusteru (např. kubeless, knativ nebo fn).
Co stojí za zmínku je, že knihovny, které v naších funkcích používáme, mohou obsahovat zranitelnosti, o kterých bychom měli vědět a které bychom měli být schopni bez velkého úsilí odstranit upgradem knihovny na vyšší verzi.
Když už jsem se zmínil o zranitelnostech v knihovnách, tak by se určitě dalo napsat pár dalších řádku o skenování zranitelností, jak nasazovat patche (opravy) pomocí CI/CD pipeliny, jak pracovat s IaaC skripty a jak to všechno spojit do jednoho end to end procesu. Moderní správa cloudu je rozsáhlé téma, a tak si něco necháme na příště.
Dobrá rada na závěr: nepatchujte, redeployujte!
Postupy, které popisuji v tomto článku, jsou prověřené mnoha lety a tisíci firmami po celém světě. K tématu najdete celou řadu detailních technických článků a návodů. Takže stručně řečeno:
- Nebojte se změny – nejsme doktoři, takže když uděláme chybu, nikdo neumře. (Rada je určena pouze těm, kdo neprovozují životně důležité IT systémy.)
- Neryjte své pole rýčem, ale pořiďte si traktor!
- Mějte velké plány, ale klidně začněte malými krůčky.
- Pokud si s něčím nebudete vědět rady, tak se na nás obraťte. Rádi pomůžeme i s jinými tématy, než je správa cloudu.



