Fault injection or break it yourself!

For a long time, we said, "If it works, don't touch it!" It's simply better not to touch running technology, lest our road to failure be paved with good intentions. But in recent years we have a new approach - let's "break" our own systems on an ongoing basis so that we can handle real incidents later. Isn't that nonsense? If not, how to do it? And how does cloud technology help us do that?
Kamil Kovář
The idea of generating targeted outages and errors on infrastructure is not new or foreign. Every large company that provides IT services at a professional level performs regular disaster recovery tests (for which we have developed a tool to automate TaskControl - Automation of real-time activity coordination).
So the company is testing large-scale outage, i.e. macroscopic approach. It shuts down one large part of the infrastructure, typically systems in one datacenter, and turns on all services in an alternate location.
I'm sure you run DR tests in your company too and you can rely on the robustness of the environment, right?
Targeted small-scale outagesthat is to say microscopic approach, is a relatively new issue and has its origins in the first decade of this century. In the same way that we build systems with resilience to the failure of a datacenter, we naturally build them with resilience to the failure of a smaller unit, a virtual server, a container or an individual service. We use technology to blackout or Outage-free restart services.
Infrastructure accessibility
We have historically addressed robustness:
- Infrastructure at the level of datacenters (dual power sources, grid cooling, control, etc.),
- at the level of hardware (redundant power supply, internal cooling, disk RAID, etc.),
- at the level of virtualization (OS or container).
When providing cloud services, all of the following IT components are under the responsibility of the cloud provider. Despite all the redundancy, we get a relatively low availability guarantee.
What does Amazon have to say about this? AWS will use commercially reasonable efforts to make Amazon EC2 and Amazon EBS ... of at least 99.99%, in each case during any monthly billing cycle (the "Service Commitment").
Microsoft at a glance Service Level Agreements Summary | Microsoft Azure guarantees for individual virtual machines network availability 99.9 %.
For details on infrastructure services in the cloud I recommend the article by Jakub Procházka (6) Building the Foundations: Infrastructure as a Service | LinkedIn.
(V ORBIT is also preparing a December special on the topic of high availability in the cloud for more details. To make sure you don't miss it, just follow the company's LinkedIn profile.)
Software availability
Ideal for achieving really high availability is not relying on infrastructure availability (although for less critical applications is a sufficient approach) if 99.9 % are guaranteed to match the target SLA. Even there, of course, I have to take care of backup and service restoration method.
For critical applications, we therefore continue to achieve high availability at software level. Primarily on middleware (in the sense of cluster technologies at the application platform or database level), or in the code of the software solution itself.
The goal is for the software to enable:
- redirecting or splitting queries on the integration, user, or data interface, usually by load balancer services or network services,
- similar load distribution calculations and transformations at the application layer,
- redirect within active/passive clusters or active/active clusters at the database layer.
For example, we may get a sympathetic architecture like this:
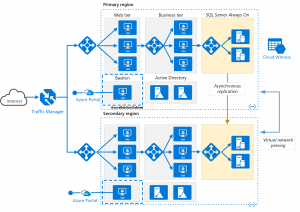
These functionalities are supported by native cloud services such as scalesets, application gateways and load balancers, highly available databases and more.
An important condition is software capability work in the configuration load distributioni.e. be configured to multiple redundant components performing the same operation.
Some layers may use a stateless module to handle the incoming request regardless of the historical session progress (i.e., communication with the counterparty). Such a component does not retain any data and can be removed at any time.
Other times we have to take into account some loss of session continuity if the module is stateful and keeps a running transaction in temporary memory.
It is generally recommended to keep sessions in a fast distributed repository such as AWS Redis or Azure Cache for Redis.
User experience on a classic example
Let's imagine a situation where I order goods in an e-shop and recalculate the price in the shopping cart after adding another item. Sudden fall of a container with a stateless component to calculate the total price, I will only note that the action did not last one second but three, because the calculation call had to be repeated against another container. I proceed normally with the purchase.
When selecting the delivery method and location, you may find that the user interface still shows a blank selection after the selection has been made. This time it has failed state component, which was responsible for site selection, the map base and the list of sampling points. Instead of selecting a delivery box in our village, an error was returned to the API, which as a user I will not know about. I go back to selecting the drop-off point again, and a different instance of the component now walks me through the same steps with only a slight loss of user experience.
How not to test on customers
Here we have reached the essence of why we use fault injection within the field of chaos engineering. We always perform functional and acceptance tests so that we can be sure that the application executes the code correctly.
But we're not used to crash test individual redundant componentsi.e. whether the behaviour of the application is still in line with the expected UX (user experience). We actually perform this with a large degree of uncertainty in production environments down to the customers of the service.
That attitude is costing us:
- Reputational riskif redundancy is insufficient and UX is very poor. This is a very common case known among others from government deliveries.
- Unnecessary costsbecause we don't know how to set the target robustness. There is a risk that we have set the individual application layers unevenly and unnecessarily generously. In cloud services, robustness is usually set by a few lines of code, which result in several orders of magnitude higher cost. Incidentally, you can read about cloud costs more here.
Fault injection and chaos engineering
The field of error insertion itself is not limited to IT infrastructure, but also includes software developmentwhere it is possible to deliberately break certain parts of the code (products such as. ExhaustIF a Holodeck). It is also used in other disciplines, including physical manufacturing (think of aerospace engineering and verifying the robustness of the systems of a satellite that then flies in orbit for twenty years).
What do we need in our industry? In the operation of IT systems (operations) it is important for us to be able to insert possible errors into the infrastructure:
- Scheduled - All operations and support functions must be aware of planned partial outages,
- Controlled - I must not indiscriminately break too much of the infrastructure,
- With the measurement - I must be able to assess the impact of errors on the quality of service.
He is considered a pioneer in the field Netflixwho introduced chaos engineering way back around 2011 and developed his own tool ChaosMonkey for targeted disruption of compute resources, network components and component states. The tool was soon published as open source.

ChaosMonkey was soon enriched by the addition of Simian Army with a more sophisticated approach to introducing faults, enabling better tuning of the necessary resilience of systems. Chaos engineering has been gradually introduced by all major service companies such as Google, Microsoft, Facebook/Meta and others.
But that doesn't mean it's a discipline for large companies with CDNs (content delivery networks) and large-scale services. Fault injection should gradually become part of the processes in all IT service companies with high availability. Anyone can easily try testing on their existing environment using the tools described below.
Tool support
In a short time, several interesting instruments with varying degrees of detail were created. Breaking is traditionally a simple activity. Here it includes shutdowns, component reboots, artificial load generation and reconfigurations.
Complex is the control and monitoring part, where I need to see the behavior of applications and components that are intentionally affected by the error. After ChaosMonkey tools like Gremlin, ChaosMesh, ChaosBlade, Litmus and others. Support for fault injection is also available for the well-known Istio.
Let's describe here an extended tool Gremlin and new native tools from major cloud providers AWS FIS a Azure Chaos Studio.
Gremlin
Gremlin (dating back to 2014) is a well-known online bug-insertion tool with agent support and connection to cloud services.

Its interface is simple, as is its use. The agent must be installed on each guest that is to become its target.
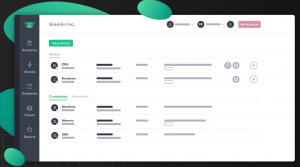
Basically. Gremlin Allows attacks on resources in virtual machines or containers, including overloading, restarting, or shutting them down, on databases, or on networks. It can overload CPU, memory and I/O, for example it can change system time or kill specific processes. Causes network communication drops, causes network latency or prevents access to DNS.
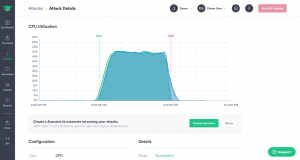
The scenarios allow you to combine attacks and monitor the status of affected target components. Imagine, for example, periodically verifying that scalesets are functioning properly by purposely overloading nodes in a set and monitoring whether new nodes are turning on fast enough.
Gremlin Supported by Service Discovery within the target environment. It can detect system instability and stop attacks in time before they cause service disruption.
For testing within the same team can Gremlin to use at no charge.
AWS Fault Injection Simulator (AWS FIS)
New service (2020) AWS FIS testing EC2, ECS, EKS, RDS by shutting down or restarting machines and services is also part of Amazon's portfolio. This is very similar fault injection logic, adapted to the AWS environment, including the ability to define tests as JSON documents. The integration makes it unnecessary to use an agent for most of the actions performed, except when you need to load resources.
V AWS FIS You create events Above Targets according to available conditions. Action chaining allows you to define advanced scenarios. It is possible to define a condition under which the test will end (if I significantly disrupt the functionality of the environment). The whole concept allows integration into the CD pipeline.
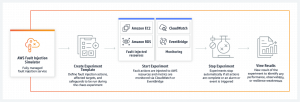
The account under which the tests run, which must have access to the resources it operates, has fairly high privileges and needs to be accessed as such.
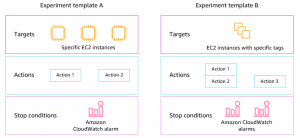
AWS FIS is paid per use for the number of actions performed.
Azure Chaos Studio
At the time of writing, the tool is Azure Chaos Studio for Microsoft Azure in Preview, and is therefore until April 2022 provided for testingbefore he goes on the pay-per-use model.
The concept of the tool is similar to the previous ones, where on one side in Chaos Studio I create experimentssuch as stress tests, and in Application Insights I continue to monitor the behavior of the source. The errors I can generate are again CPU, virtual or physical memory loads, I/O, resource restarts, system time changes, changes and failures on container infrastructure, and more. The list is gradually growing to include the most used cloud resources in Azure. The presence of APIs will enable integrations with other third-party products.
Let's design systems better
The discipline of chaos engineering and controlled insertion of bugs into infrastructure is developing promisingly. With cloud services, we get our hands on extensive infrastructure and advanced tools. We can easily and safely model outages as they actually occur statistically (we can base this on provider figures for component availability).
We match the resulting behavior of the infrastructure, which is under the pressure of managed outages, to the custom configuration of the infrastructure and software tools so that the resulting number matches the SLA for the application provided. With fault injection tools, we have the ability to stop designing robustness by looking out of the window, but by drawing on tangible experience and the language of numbers.
When do you think the adoption of chaos engineering will happen in your company? Let me know in the article discussion if you would dare to adopt this approach today!



