Fault injection neboli rozbij si to sám!

Dlouho jsme si říkali „Když to funguje, tak na to nesahej!” Do běžících technologií je zkrátka lepší nesahat, aby naše cesta k výpadku nebyla dlážděna dobrými úmysly. Ale poslední roky tu máme přístup nový – „rozbíjejme“ si průběžně systémy sami, abychom později ustáli reálné incidenty. Není to nesmysl? Pokud ne, jak na to? A jak nám v tom nahrávají cloudové technologie?
Kamil Kovář
Myšlenka na cílené generování výpadků a chyb na infrastruktuře není nová nebo cizí. Každá velká firma, která IT služby poskytuje na profesionální úrovni, provádí pravidelné testy disaster recovery (pro jejichž automatizaci jsme vyvinuli nástroj TaskControl – Automatizace koordinace aktivit v reálném čase).
Firma tedy testuje výpadek ve velkém měřítku, tj. makroskopickým přístupem. Vypíná řízeně jednu velkou část infrastruktury, typicky systémy v jednom datacentru, a zapíná všechny služby v náhradní lokalitě.
Ve vaší firmě určitě DR testy provádíte také a můžete se na robustnost prostředí spolehnout, pravda?
Cílené výpadky v malém měřítku, tedy mikroskopický přístup, je záležitost poměrně nová a má počátky v první dekádě tohoto století. Stejně, jako stavíme systémy s odolností proti výpadku datacentra, stavíme je samozřejmě s odolností proti výpadku menších jednotek, virtuálního serveru, kontejneru nebo jednotlivé služby. Používáme technologie pro výpadkový nebo bezvýpadkový restart služeb.
Infrastrukturní dostupnost
Robustnost historicky řešíme:
- infrastrukturně na úrovni datacentra (duální zdroje elektřiny, chlazení sítí, řízení atd.),
- na úrovni hardware (redundantní napájení, interní chlazení, diskový RAID apod.),
- na úrovni virtualizace (OS nebo kontejneru).
Při poskytování cloudových služeb jsou všechny tyto IT komponenty v gesci poskytovatele cloudu. Přes všechnu redundanci dostáváme relativně nízkou záruku na dostupnost.
Co nám k tomu řekne Amazon? AWS will use commercially reasonable efforts to make Amazon EC2 and Amazon EBS … of at least 99.99%, in each case during any monthly billing cycle (the “Service Commitment”).
Microsoft na přehledu Service Level Agreements Summary | Microsoft Azure pro jednotlivé virtuální stroje garantuje síťovou dostupnost 99,9 %.
Pro detaily k infrastrukturním službám v cloudu doporučuji článek kolegy Jakuba Procházky (6) Stavíme základy: Infrastructure as a Service | LinkedIn.
(V ORBITu také připravujeme prosincový speciál na téma vysoké dostupnosti v cloudu, kde se dozvíte více detailů. Abyste ho nezmeškali, stačí sledovat firemní profil na LinkedIn.)
Softwarová dostupnost
Ideální pro dosažení opravdu vysoké dostupnosti je nespoléhat se na infrastrukturní dostupnost (ačkoli pro méně kritické aplikace je to přístup dostačující), pokud je garantovaných 99,9 % odpovídajících cílové SLA. I tam se samozřejmě musím postarat o zálohování a způsob obnovení služeb.
Pro kritické aplikace proto dále dosahujeme vysoké dostupnosti na úrovni software. Primárně na middleware (ve smyslu clusterových technologiích na úrovni aplikační platformy nebo databáze), nebo v kódu samotného softwarového řešení.
Cílem je, aby software umožňoval:
- přesměrování nebo rozkládání dotazů na integračním, uživatelském nebo datovém rozhraní, obvykle službami load balanceru anebo síťovými službami,
- obdobné rozkládání zátěže výpočtů a transformací na aplikační vrstvě,
- přesměrování v rámci active/passive clusterů nebo active/active clusterů na databázové vrstvě.
Může nám vzniknout třeba takováto sympatická architektura:
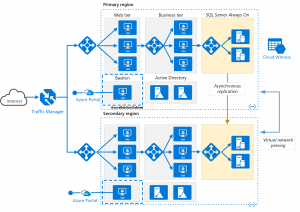
Tyto funkcionality jsou podporovány nativními službami cloudu, jako jsou scalesety, aplikační brány a load balancery, vysoce dostupné databáze a další.
Důležitou podmínkou je schopnost software pracovat v konfiguraci rozkládání zátěže, tj. být nakonfigurován na více redundantních komponent provádějících stejnou operaci.
Některé vrstvy mohou k tomu používat bezstavový (stateless) modul, který odbaví příchozí požadavek bez ohledu na historický průběh session (tedy komunikace s protistranou). Taková komponenta si nedrží žádná data a může být kdykoli odstraněna.
Jindy musíme počítat s určitou ztrátou kontinuity session, pokud je modul stavový a udržuje si v dočasné paměti nějakou rozběhlou transakci.
Obecně se doporučuje držet sessions v rychlém distribuovaném úložišti, jako je AWS Redis nebo Azure Cache for Redis.
Zkušenost uživatele na klasickém příkladu
Představme si situaci, kdy v e-shopu objednávám zboží a v nákupním košíku po přidání další položky přepočítávám cenu. Náhlý pád kontejneru s bezstavovou komponentou pro výpočet celkové ceny zaznamenám pouze tak, že akce netrvala jednu vteřinu ale tři, protože volání výpočtu muselo být opakováno proti jinému kontejneru. Pokračuji normálně dál v nákupu.
Při výběru způsobu a místa dodání zase může dojít k situaci, kdy po provedení výběru bude uživatelské rozhraní stále ukazovat prázdný výběr. Tentokrát selhala stavová komponenta, která měla na starosti výběr místa, mapový podklad a seznam odběrných míst. Namísto výběru donáškového boxu v naší obci byl API rozhraní vrácen error, o kterém se jako uživatel nedozvím. Znovu se vrátím do výběru odběrného místa a jiná instance komponenty mě nyní provede stejnými kroky jen s mírnou ztrátou uživatelského komfortu.
Jak netestovat na zákaznících
Zde jsme došli k meritu toho, proč používáme fault injection v rámci oboru chaos engineering. Vždy provádíme funkční a acceptance testy tak, abychom si byli jistí, že aplikace provádí napsaný kód správně.
Nejsme ale zvyklí testovat havárie jednotlivých redundantních komponent, tj. zda je chování aplikace ještě v souladu s očekávanou UX (user experience). Toto ve skutečnosti provádíme s velkou mírou nejistoty v produkčních prostředích až na zákaznících služby.
Takový přístup nás stojí:
- Reputační riziko, pokud je redundance nedostatečná a UX velmi špatná. To je velmi častý případ známý mj. z dodávek do státní správy.
- Zbytečné náklady, protože nevíme, jak cílovou robustnost nastavit. Hrozí, že jednotlivé aplikační vrstvy máme nastaveny nerovnoměrně a zbytečně velkoryse. V cloudových službách je robustnost obvykle nastavitelná několika řádky kódu, které mají za následek o několik řádů vyšší cenu. O nákladech v cloudu si ostatně můžete přečíst více zde.
Fault injection a chaos engineering
Samotný obor vkládání chyb se neomezuje pouze na oblast IT infrastruktury, ale týká se i vývoje software, kde je možné úmyslně narušovat určité části kódu (produkty jako např. ExhaustIF a Holodeck). Používá se i v jiných disciplínách včetně fyzické výroby (představte si kosmické inženýrství a ověřování robustnosti systémů satelitu, který potom létá na orbitě dvacet let).
Co potřebujeme v našem oboru? V provozu IT systémů (operations) je pro nás důležité umět vkládat možné chyby do infrastruktury:
- Plánovaně – všechny složky provozu a podpory musí vědět o plánovaných částečných výpadcích,
- Řízeně – nesmím bez rozmyslu rozbít příliš vekou část infrastruktury,
- S měřením – musím být schopen dopad chyb na kvalitu služby vyhodnotit.
Za pionýra oboru je považován Netflix, který zavedl chaos engineering již za dávných časů okolo roku 2011 a vyvinul vlastní nástroj ChaosMonkey pro cílené narušování compute zdrojů, síťových součástí a stavů komponent. Nástroj byl brzy publikován jako otevřený kód.

ChaosMonkey byl brzy obohacen o přídavek Simian Army s propracovanějším přístupem v zavádění chyb umožňující lepší ladění potřebné odolnosti systémů. Chaos engineering postupně zavedly všechny velké společnosti poskytující služby jako Google, Microsoft, Facebook/Meta a další.
To ovšem neznamená, že se jedná o disciplínu pro velké společnosti s CDN (content delivery network) a s rozsáhlými službami. Fault injection by se měla postupně stát součástí procesů ve všech IT společnostech poskytujících služby s vysokou dostupností. Testování si může snadno vyzkoušet každý na svém stávajícím prostředí s využitím nástrojů popisovaných dále.
Nástrojová podpora
V krátkém čase vzniklo více zajímavých nástrojů s různou mírou detailu. Rozbíjení je tradičně jednoduchá činnost. Zde zahrnuje vypínání, restarty komponent, generování umělé zátěže a rekonfigurace.
Komplexní je část řízení a monitorování, kde potřebuji vidět chování aplikací a komponent, které jsou úmyslnou chybou zasaženy. Po ChaosMonkey se objevili nástroje jako Gremlin, ChaosMesh, ChaosBlade, Litmus a další. Podporu pro fault injection má například i známé Istio.
Popišme si zde rozšířený nástroj Gremlin a nové nativní nástroje hlavních cloudových poskytovatelů AWS FIS a Azure Chaos Studio.
Gremlin
Gremlin (datující se do roku 2014) je známý online nástroj pro vkládání chyb s agentovou podporou a s napojením do cloudových služeb.

Jeho rozhraní je jednoduché, stejně jako použití. Agent musí být nainstalován na každý host, který se má stát jeho cílem.
V zásadě Gremlin umožňuje útoky na zdroje ve virtuálních strojích nebo kontejnerech včetně jejich přetížení, restart nebo vypnutí, na databáze či na sítě. Umí přetížit CPU, paměť i I/O, umí například změnit systémový čas nebo zabíjet specifické procesy. Způsobí zahození síťové komunikace, vyvolá síťovou latenci nebo zabrání v přístupu k DNS.
Scénáře umožňují útoky kombinovat a sledovat stav postižených cílových komponent. Představte si například pravidelné ověřování správné funkce scalesetů, kdy cíleně přetěžujete nody v setu a sledujete, zda se nové nody zapínají dostatečně rychle.
Gremlin podporuje Service Discovery v rámci cílového prostředí. Umí detekovat nestabilitu systémů a zastavit útoky včas, než způsobí narušení služby.
Pro testování v rámci jednoho týmu lze Gremlin používat bez poplatků.
AWS Fault Injection Simulator (AWS FIS)
Nová služba (2020) AWS FIS testující EC2, ECS, EKS, RDS vypínáním nebo restartem strojů a služeb je i součástí portfolia Amazonu. Jedná se o velmi podobnou logiku fault injection, přizpůsobenou AWS prostředí, včetně možnosti definovat testy jako JSON dokumenty. Díky integraci není na většinu prováděných akcí nutné použít agenta, s výjimkou, kdy potřebujete zatížit zdroje.
V AWS FIS vytváříte akce nad cíli podle dostupných podmínek. Řetězení akcí umožňuje definovat pokročilé scénáře. Je možné stanovit podmínku, za které test skončí (pokud naruším výrazně funkcionalitu prostředí). Celý koncept umožňuje integraci do CD pipeline.
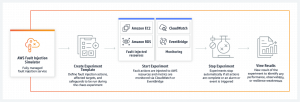
Účet, pod kterým testy běží a který musí mít přístup ke zdrojům, kterými operuje, má poměrně vysoká oprávnění a je třeba k němu tak přistupovat.
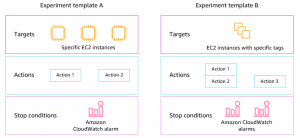
AWS FIS je placeno per use za počet provedených akcí.
Azure Chaos Studio
V době psaní článku je nástroj Azure Chaos Studio pro Microsoft Azure v Preview, a proto je do dubna 2022 poskytován k testování, než naběhne na placený per-use model.
Koncept nástroje je podobný předchozím, kdy na jedné straně v Chaos Studiu vytvářím experimenty, například zátěžové, a v Application Insights dále sleduji chování zdroje. Chyby, které mohu vytvářet, jsou opět zátěže na CPU, virtuální nebo fyzickou paměť, I/O, restarty zdrojů, změny systémových časů, změny a selhání na kontejnerové infrastruktuře a další. Seznam se postupně rozšiřuje o nejpoužívanější cloudové zdroje v Azure. Přítomnost API umožní integrace s dalšími produkty třetích stran.
Pojďme designovat systémy lépe
Disciplína chaos engineering a řízené vkládání chyb do infrastruktury se slibně rozvíjí. S cloudovými službami dostáváme do rukou rozsáhlou infrastrukturu a vyspělé nástroje. Můžeme snadno a bezpečně modelovat výpadky tak, jak statisticky skutečně nastávají (můžeme vycházet z čísel poskytovatelů o dostupnosti komponent).
Výslednému chování infrastruktury, která je pod tlakem řízených výpadků, přizpůsobíme vlastní konfiguraci infrastruktury a softwarových nástrojů tak, aby výsledné číslo odpovídalo SLA na poskytovanou aplikaci. S fault injection nástroji máme možnost přestat designovat robustnost pohledem z okna, ale vycházet z hmatatelných zkušeností a z řeči čísel.
Kdy si myslíte, že k adopci chaos engineeringu dojde ve vaší firmě? Dejte mi vědět v diskuzi k článku, jestli byste si na tento přístup troufli už dnes!



