Vysoká dostupnost služeb v cloudu – jak na ni?

V tomto článku cloudové encyklopedie si povíme něco o návrhu vysoké dostupnosti služeb neboli high availability (HA). Jak jí dosáhnout, z čeho poskládat, jak velká by měla být? Čemu se říká vysoká dostupnost – je to 99,5 %, 99.9 % nebo 99,95 %? A je to jen o vysoké dostupnosti cloudových služeb, nebo do věci vstupují další hlediska jako obnova dat po havárii? Pojďme si ukázat, jaké možnosti máme v cloudu a co všechno je potřeba zohlednit.
Lukáš Hudeček
Vysoká dostupnost služeb – obecná charakteristika a co je to SLA
Obecně platí, že návrhy vysoké dostupnosti vycházejí z byznysových potřeb, které má většina společností definovaných v business continuity strategiích, analýzách dopadu a na ně navázaných SLA.
Pří plánování vysoké dostupnosti musíme nejprve definovat, jak velká má dostupnost být. A vycházet musíme z toho, co se stane, když část nebo celý systém nepoběží. Je přitom nezbytné definovat všechny druhy dopadů – operativní, finanční, dopady na vztah se zákazníkem, celkové dopady na byznys.
Z těchto definic se spočítají maximální přípustné doby výpadku. Vznikne podklad pro architekturní design, který bude zohledňovat požadované úrovně dostupnosti služeb nazývané servise-level agreement, dále jen SLA.
SLA definuje parametry dodávané služby jako její popis, provozní dobu, reporting, bezpečnostní parametry, měření výkonu služby a hlavně spolehlivost a dostupnost služby. V IT hantýrce většinou údaj SLA XX % vyjadřuje právě procentuální dostupnost služby.
Pro ilustraci SLA 99,9 % vyjadřuje maximální dobu výpadku:
- 1 min 26 s denně
- 10 min 4 s týdně
- 43 min 49 s měsíčně
- 2 h 11 min 29 kvartálně
- 8 h 45 min 56 s ročně
Abychom dosáhli vysokého SLA, je potřeba definovat robustní, odolný a spolehlivý architekturní design aplikace nebo celého prostředí tak, aby všechny použité komponenty jako celek splňovaly požadovanou úroveň služeb.
Obecně platí, že celý systém je tak robustní jako jeho nejslabší článek, což bývá ve snaze ušetřit ten nejčastější problém.
Navíc musíme architekturu navrhovat tak, aby s udržením SLA počítaly i všechny úlohy maintenance jako:
- aktualizace a upgrady,
- obnovy dat v případě poškození nebo hackerského útoku,
- deploymentu služby a prostředí (CI/CD).
Dopady výpadků
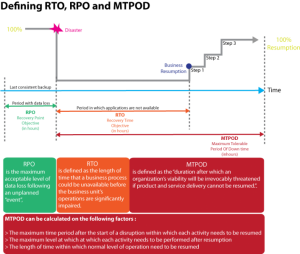
Dosažení vysoké dostupnosti (tedy SLA začínajícího „třemi devítkami“: 99,9 %) nebývá levná záležitost. Hodnota SLA proto musí vycházet ze zpracované analýzy dopadu BIA (business impact analysis), ve které jsou definovány dopady výpadku a z ní vycházející časy RPO/RTO/MTPOD, které udávají:
- RPO (recovery point objective) – maximální čas ztráty dat,
- RTO (recovery time objective) – maximální dobu obnovy dat,
- MTPOD (max tolerable period of down time) – maximální dobu obnovy celého systému včetně nápravných kroků po obnově dat.
Vyčíslení dopadu
Po definici parametrů RTO/RPO/MTPOD potřebujeme mít vyčíslený dopad, tedy kolik bude stát, když systémy nepojedou například 24/48/72 hodin. Teprve pak bývá finanční ředitel (nebo někdo, kdo drží rozpočet) ochotný diskutovat o tom, jak robustní typ implementace vysoké dostupnosti nasadit, resp. jaká rizika a případné finanční ztráty je nutné akceptovat.
Pokuta/sleva
Posledním důležitým parametrem je, co se stane v případě porušení SLA ze strany dodavatele služeb. Pokuta bývá stanovena dle doby výpadku částí služby nebo nedostupnosti celé služby. Většinou je pokuta vyčíslena jako maximálně jedna měsíční platba za službu.
Protože finanční ztráta při výpadku bývá mnohonásobně vyšší než dodavatelem zaplacená pokuta, je nezbytné navrhovat skutečně robustní a odolný design.
Architektura služeb v cloudu
Poskytovatelé cloudu umožňují uživatelům jejich služeb dosáhnout široké škály úrovní dostupnosti. Většinou toho ovšem nedosahujeme magickým konfiguračním posuvníkem služby, ale správnou redundantní architekturou s využitím více balancovaných komponent a umístěním do více zón dostupnosti.
Proto se při návrhu architektury v cloudu zaměříme na platformní služby (PaaS), o nichž byla řeč v tomto článku. PaaS samy o sobě splňují požadavek robustnosti, skládají se z více komponent a mají definované SLA. Zároveň se PaaS dají provozovat ve více zónách dostupnosti, jsou škálovatelné a mají ošetřené havarijní scénáře, včetně zálohování a možného rychlého re-deploymentu služby.
V případě použití infrastrukturních služeb typu klasické VM je dobré zvážit umístění do scale-setu. Ten umožnuje zajistit automatické spouštění dalších instancí, podle plánu, a zároveň podporuje zóny dostupnosti. Stejně tak musíme konfigurovat všechna uložiště, počínaje imagem, ze kterého nasazuji, až po vlastní managed disky pod jednotlivými VM skrz zóny dostupnosti.
- Přehled SLA Microsoft Azure https://azure.microsoft.com/cs-cz/support/legal/sla/summary/
- Přehled SLA AWS https://aws.amazon.com/compute/sla/
Vysoce dostupná architektura aplikace
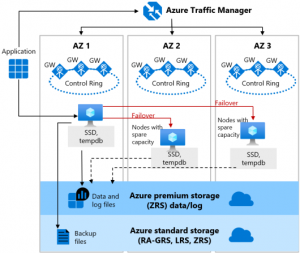
Jestli chci mít aplikace opravdu robustní a eliminovat všechna možná rizika (jako je ztráta datacentra), musím architekturní design komponent navrhovat přes regiony a zóny. Zároveň musím zvolit automatizovaný deployment a v případě ztráty nebo poškození provést redeploy. Na obrázku je příklad ASP.NET a SQL server scénář vícevrstvé architektury ve dvou variantách SLA:
- První varianta má SLA 99,95 %: komponenty jsou rozděleny přes dva regiony a jednotlivé prostředky jsou v rámci availibility setu. O celý případný failover se stará Azure trafic manager popsaný v textu dále.
- Druhá varianta má SLA 99,99 %: od první varianty se liší rozdělením v rámci dvou regionů ještě na dvě availibility zóny. To je maximální možné SLA blížící se ke 100 % s dobou výpadku nejvýše 52 min 35 s za rok.
Zvýšení SLA na 99,99 % jsme dosáhli rozdělením prostředků do availibility zón, tedy do dvou samostatných fyzických lokací v rámci regionu, zatímco availibility set je umístění v rámci jedné fyzické lokace.
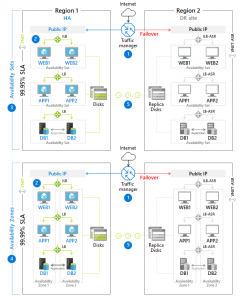
Vysoká dostupnost služeb začíná u regionů a zón
Základním stavebním prvkem vysoké dostupnosti globálních servisních providerů jsou regiony a zóny. U obou klíčových zástupců globálních service providerů (Amazon Web Services a Microsoft Azure) je tato funkcionalita obdobná.
Region je kompletně izolované prostředí, které nesdílí žádnou infrastrukturu s jiným regionem. Jednotlivé regiony jsou propojeny pouze páteřní konektivitou. Regiony slouží jako globální fault-domains (geograficky oddělená a izolovaná datacentra, kdy výpadek jednoho nijak neovlivní druhé) a mají za cíl kompletně oddělit prostředí pro business continuity & disaster recovery řešení.
Obvykle není možné nativně propojit interní sítí dva virtuální servery z různých regionů, nicméně mezi regiony je možné replikovat data. Datová konektivita mezi jednotlivými regiony bývá zpoplatněna, v porovnání s internetovou konektivitou je však levnější.
Zónou je myšleno konkrétní datové centrum (nebo několik blízkých datových center v jedné lokalitě) v rámci regionu. Každá zóna je plně redundantní a nesdílí s jinou zónou žádné infrastrukturní prvky (chladicí zařízení, diesel-generátory, síťovou infrastrukturu a další).
Zóny jsou mezi sebou propojeny vysokokapacitní sítí s minimální latencí a konektivita v rámci zón nebývá zpoplatněna. Virtuální servery (či jiné služby) mohou být umístěny v různých zónách v rámci regionu a jsou propojeny interní sítí.
Přehled cloudových komponent, které se vyplatí znát
Redundance virtuálních instancí
Azure VM Scale set nebo AWS EC2 Auto Scaling jsou službami automatického škálování počítačů. Umožňují během několika minut vytvořit a nasadit stovky virtuálních počítačů s integrovaným vyrovnáváním zatížení a automatickým škálováním na základě šablon. Při kombinaci VM a spot instancí v jedné sadě lze dosáhnout velké optimalizace finančních nákladů. Při kombinaci VM scale setu a umístění do minimálně dvou zón dostupnosti lze dosáhnout SLA 99,99 %.

Redundance kontejnerů
Azure AKS nebo Amazon EKS jsou Enterprise Kubernetes službami, které pokrývají scénáře vysoké dostupnosti, škálovatelnosti, procesu nasazení, správy a vyhodnocení. S podporou moderních aplikací, které se vyvíjí jako Microservices architecture a mají v Kubernetes plnou podporu.
Součástí řešení jsou i různé balancovací nástroje, které umí škálovat počet spuštěných instancí. Do AKS/EKS poolu můžu přidat libovolné typy VM ze všech dostupných řad a je možné využít i spot instance, které jsou optimální pro zpracování batch úloh. Pro Build & Deploy využívám pipeline nástroje popsané níže.
Je dobré vědět, že deployment Kubernetes clusteru v cloudu nic nestojí, účtují se až jednotlivé spuštěné VM v poolech.
A co se stane, když váš kontejner „umře“? Okamžitě nastartuje nový (stejný) a vy se nemusíte o nic starat. Stejně tak to funguje při spadnutí podkladového VM. Jen je potřeba podkladové VM a kontejnery správně rozložit, aby byly při výpadku stále ve vysoké dostupnosti 1+n. Tento model je ideální jak pro backend tak frontend služby.
Toto téma jsme detailně rozebírali v minulém článku.
Redundance aplikací
Azure App Service je velmi zajímavá alternativa ke Kubernetes clusteru. Umožnuje taktéž spouštění mnoha instancí kódu nebo kontejneru zabalených v Dockeru. Tato služba pro škálování webových aplikací má SLA 99,95 % v premium tieru nebo v dedikovaném isolated tieru.
Služba obsahuje i load balancer pro distribuci zátěže a podporuje privat endpointy pro napojení do vnitřní sítě. Pro publikaci obsahu do internetu se většinou používá v kombinací s Azure Application Gateway jako L4/L7 aplikačním firewallem. Stejně jako ostatní služby plně podporuje CI/CD automatický deployment.
Azure Functions jsou obdobou AWS Lambda a rovněž umožňují spuštění serverless kódu i v podobě kontejneru. Platí se za čas a využitou RAM, každý měsíc je relativně velké množství požadavků zdarma.
Azure Loadbalancer nebo AWS Elastic Load Balancing jsou platformní služby, které vyrovnávají zatížení distribucí příchozích toků, které dorazí na front-end služby a vyrovnávají zatížení do instancí fondu back-endu na čtvrté vrstvě (L4) modelu Open Systems Proconnection (OSI).
Kromě klasických load balancerů, které pracují na L4 vrstvě, poskytují cloud provideři i pokročilejší aplikační load balacery (v Azure Application gateway), které pracují na sedmé vrstvě (L7) OSI modelu, a podporují tak některé další funkce jako například cookie-based session affinity.
Tradiční load balancery na čtvrté transportní vrstvě pracují na úrovni TCP/UDP a směrují traffic dle zdrojové IP adresy a portu na cílovou IP adresu a port. Oproti tomu aplikační load balancery mohou provádět rozhodnutí na základě konkrétního HTTP požadavku. Dalším příkladem může být směrování dle příchozí URL.
Síťová redundance
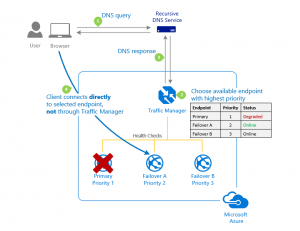
Traffic manager je DNS-based load balancer, který umožňuje distribuovat provoz pro aplikace dostupné z internetu napříč regiony. Zároveň poskytuje pro tyto veřejné endpointy vysokou dostupnost a rychlou odezvu.
Co to všechno znamená? Zjednodušeně jde o způsob, jak směrovat klienty na odpovídající endpointy. Traffic manager má několik možností, jak toho docílit:
- priority routing
- weight routing
- performance routing
- geographic routing
- multivalue routing
- subnet routing
Tyto metody lze kombinovat pro zvýšení komplexnosti výsledného scénáře tak, aby byl co nejvíce flexibilní a sofistikovaný.
Zároveň je automaticky monitorováno zdraví jednotlivých regionů a pokud dojde k výpadku, je provoz přesměrován.
Redundance RDS
Azure PaaS db services nebo Amazon RDS (Relational Database Service) nabízejí platformní databázové služby zahrnující:
- MYSQL
- PostgreSQL
- Maria DB
- Oracle
- SQL server
- Aurora DB (AWS)
- Cosmos DB (Azure)
- SQL server Managed Instance (Azure).
- a další
Prakticky u všech typů DB lze zvolit 1+n instancí, vybrat typ HW, na kterém služba poběží, využít Premium SSD nebo ultra SSD disky. Stejně jako u ostatních služeb je možné zvýšit odolnost deploymentem přes více zón dostupností, kde se můžeme v některých scénářích dostat na SLA 99,99 %. Další výhodou více replik je možnost využít je k optimalizaci čtecích operací.
Vysoká dostupnost a úložiště v cloudu
V cloudech je mnoho druhů uložišť a nebudeme každé do detailu rozebírat. Většina uložišť zmíněných níže má SLA začínající na 99,9 % až po scénáře vysoké dostupnosti s rozložením dat skrz regiony a zóny s SLA dosahujícím 99,999 %.
V Azure to jsou Blob Storage, Azure Files, Azure Data Lake, v případě potřeby vysokého výkonu a nízké latence Azure NetApp Files.
V AWS jsou to služby Amazon S3, EFS Elastic File System a EBS Elastic Block Store jako vysoce výkonná a redundantní storage.
I u nejvyšších SLA uložišť je třeba počítat s tím, že můžu o data někdy přijít. Pravděpodobnost je sice minimální (0,001 %, tedy „maximálně jednou za 10 let“), přesto platí, že vše musím zálohovat.
Distribuce obsahu
Azure CDN (Content Delivery Network) nebo Amazon CloudFront jsou služby pro globální distribuci obsahu jako web (včetně obrázků), živý stream, video nebo velké soubory.
Služba zajišťuje celosvětově balancování a funkci cache, má uložiště takzvaný koncový bod prakticky v každé zemi. Tato platformní služba se využívá při návrhu moderních webových aplikací pro distribuci výkonu, tak aby se opakovaným stahováním velkého množství statických dat nezahlcovaly webové servery.
Komponenty, bez kterých se neobejde žádná vysoce dostupná moderní aplikace
Vysoce dostupné moderní aplikace ještě využívají služby typu:
Message queuing je služba front a výměny zpráv většinou ve formátu XML nebo JSON. Služba se používá třeba pro odesílání a příjem účetních dokladů mezi jednotlivými systémy.
V cloudu máme možnost využít Azure Service Bus, Amazon Simple Queue Service nebo vývojáři oblíbený RabitMQ, který je k dispozici také jako PaaS.
Cache jako Azure Redis Cache nebo Amazon ElastiCache jsou služby, které pomáhají optimalizovat načítání databázového obsahu. Výrazně tak urychlují načítání a běh webových aplikací a zároveň odlehčují databázovému serveru.
Obě služby jsou dostupné jako PaaS a je možné je deployvat skrz regiony a zóny dostupnosti.
Automatizace nasazení prostředí (Build & Deploy)
Při návrhu HA architektury v cloudu je potřeba počítat s automatizací deploymentu prostředí, která zkrátí čas nasazení, a zároveň zajistí udržitelnost přehlednost verzování kódu. Ideální je vše psát jako IaaC (Infrastructure as a Code) a kód spravovat v nějakém CI/CD nástroji jako Azure DevOps, Azure Pipelines nebo CI/CD AWS Pipelines.
To znamená, že kód mám uložený v repository (GitHub, Azure DevOps), kde verzuji a schvaluji změny. Build & Deploy prostředí provádím pipeline nástrojem nejprve na test/stage prostředí, kde ověřím funkčnost, rychlost deploymentu a další definované parametry. Následně pokračuji v ostrém nasazení na produkční prostředí. Vše řídím workflow a celý proces je definovaný a transparentně řízený. V případě chyby tyto nástroje umožnují porovnat jednotlivé verze kódu a zvýraznit změny.
Pro zajímavost – některé služby jako Azure App Service Plan umožnují deployvat novější verzi kódu vedle té původní, a následně mezi nimi přepnout, případně se bleskově vrátit zpět. Je to velmi užitečná funkce, kdy při vysokém SLA honím každou vteřinu výpadku.
To celé spadá pod disciplínu nazývanou release management.
Testování chaos engineeringem
Po sestavení architektury, kterou považujeme za dostatečně robustní, aby odpovídala cílovému SLA, je dobré najít prostředky a čas na implementaci otestování chaos engineeringem. O tom jsme již psali v předchozím článku.
Otestováním pravděpodobných výpadků na jednotlivých komponentách zjistíme reálné chování aplikace při částečných selháních infrastruktury a konfigurace. Jen tak si můžeme být jistí, že architektura odpovídá reálným potřebám.
Proč single VM nestačí, přestože VM má 99,9 SLA
Jeden příklad na závěr: proč single VM nestačí? I když má jedno VM poměrně vysoké SLA 99,9 %, pořád musím počítat s tím, že budeme dělat aktualizace operačního systému, databáze a aplikačních služeb. Nebo dojde k nějakému poškození dat, operačního systému disku, který nemá pevně definované SLA, nebo kterékoliv jiné provázané komponenty.
V případě využití Scale setu o minimálně dvou VM se SLA zvedá na 99,95 % pro poslední běžící instanci. Při umístění Scale setu do minimálně dvou zón dostupnosti dosáhnu na SLA 99,99 % včetně přiřazených disků.
Co tedy jako architekt musím řešit

To máte:
- sítě
- doménové záznamy
- firewally
- routing
- aplikační frontend
- aplikační backend
- scalesety
- databázi jako RDS
- loadbalancery
- CDNku
- message queuing
- aplikační cache
- automatické nasazení
- testování
Vysoká dostupnost služeb stručně
Vysoká dostupnost (HA) je v cloudu nativně podporována a lze jí nasadit výrazněji rychleji než stavět prostředí přes více datacenter v on-premise prostředí. V cloudu můžu kombinovat mnoho scénářů vysoké dostupnosti a druhů služeb. Proto je nezbytné při návrhu architektury služeb myslet nejen na vysokou dostupnost konkrétní služby, ale vždy na systém jako celek, to znamená na robustnost a odolnost celého řešení.
Dále je potřeba počítat s disciplínami jako patchmanagement všech komponent, zálohováním a testováním obnovy, tj. mít zajištěné disaster recovery řešení, jehož časy obnovy se do SLA také počítají.
A to celé musí být zastřešené business continuity managementem, kde vyhodnocuji všechna možná rizika a dopady, na jejichž základě se upravuje architekturní design, tedy životní cyklus aplikace a prostředí.
Primární výhodou cloudových řešení je detailní popis SLA všech služeb, logování a monitoring, architekturní blueprinty a best practise design architektury služeb, ze kterého lze při návrhu vycházet.
Dále je potřeba se zabývat automatizací deploymentu služby, popisem všeho jako Infrastructure as a Code oproti řešení provozovaném v on-premise prostředí, kde rozbitý hardware musím objednat, naistalovat a zapojit, v cloudu stačí „znovu nasadit“.
Jestli vás zaujala problematika vysoké dostupnosti, za pozornost určitě stojí i další články z Encyklopedie cloudu, kde najdete některá témata týkající se vysoké dostupnosti zpracována detailněji.



